
MySQL · Physical Backup · XtraBackup Backup Principle
Preface
Percona XtraBackup(PXB for short) is a backup tool developed by Percona for MySQL database physical hot standby. It supports MySQl (Oracle), Percona Server and MariaDB, and is all open source, so it’s a real conscience. Our RDS MySQL physical backup is based on this tool.
The blueprint and bug discussion of the project is on Launchpad, and the code was also on Launchpad before, but now it has been migrated to Github percona/percona-xtrabackup), the project is updated and released very fast, if you are interested you can follow :-)
This article will introduce the working principle of the backup tool, I hope it will help you.
Toolset
There are a total of 4 executable files after the package is installed, as follows.
usr |
The main ones are innobackupex and xtrabackup, the former is a perl script and the latter is a C/C++ compiled binary.
xtrabackup is used to backup InnoDB tables, not non-InnoDB tables, and has no interaction with mysqld server; innobackupex script is used to backup non-InnoDB tables, and will call xtrabackup command to backup InnoDB tables, and will also interact with mysqld server, such as adding read locks (FTWRL), getting loci (SHOW SLAVE STATUS), and so on. In short, innobackupex puts a layer of wrapping on top of xtrabackup.
In general, we want to backup MyISAM tables, although we may not use MyISAM tables ourselves, but the system tables under mysql library are MyISAM, so the backup is basically done by innobackupex command; another reason is that we may need to save the loci information.
The other two tools are relatively niche: xbcrypt is for encryption and decryption; xbstream is similar to tar, a stream file format implemented by Percona itself that supports concurrent writing. Both are used when backing up and decompressing (if the backup uses encryption and concurrency).
The main characters of this article are innobackupex and xtrabackup.
Principle
Communication method
The interaction and coordination between the 2 tools is achieved by controlling the creation and deletion of files, the main files are
- xtrabackup_suspended_1
- xtrabackup_suspended_2
- xtrabackup_log_copied
As an example, let’s see how xtrabackup_suspended_2 coordinates the two tool processes during backup
innobackupex, after starting thextrabackupprocess, waits forxtrabackupto finish backing up the InnoDB file, by waiting for the xtrabackup_suspended_2 file to be created.xtrabackupcreates the file in the specified directory after the InnoDB data is backed up, and then waits for the file to be deleted byinnobackupex.innobackupexdetects that the file xtrabackup_suspended_2 has been created, and then proceeds to the next step.innobackupexdeletes the file xtrabackup_suspended_2 after backing up the non-InnoDB tables, which informsxtrabackupthat it can continue, and then waits for xtrabackup_log_copied to be created.xtrabackupdetects that the xtrabackup_suspended_2 file is deleted, and then it can continue on.
Isn’t it incredible that it is very unreliable to control the process by the existence of files, because it is very easy to be interfered with externally, for example, if the files are deleted by mistake, or if 2 running backup control files are mistakenly placed in the same directory, just wait for the backup to be messed up, but that’s what Percona does.
The reason for this, I guess mainly because perl and C binary 2 processes, there is no good and convenient way to communicate, so it is too much trouble to get a protocol or something. But the official also think that this way is not reliable, 11 years to get a blueprint to use C rewrite innobackupex, finally implemented in version 2.3, innobackupex functions are all integrated into xtrabackup, only one binary, and for compatibility consideration, innobackupex is used as a soft chain of xtrabackup. For secondary development, 2.3 is significantly better than the previous version in terms of architecture, as it gets rid of the burden of collaboration between two processes. Considering the long existence of the perl + C architecture, most of our readers basically use the version before 2.3, the introduction of this article is also based on the old architecture (version 2.2), but the principle is the same as 2.3, only the differences in implementation.
Backup process
The whole backup process is as follows.
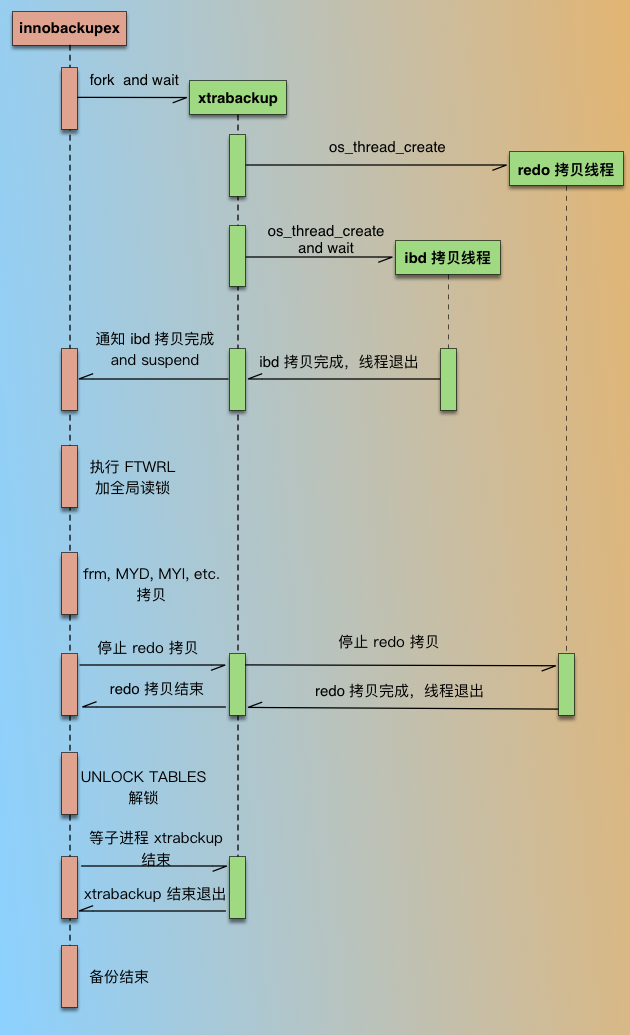
PXB backup process
innobackupex, after starting, will first fork a process, start thextrabackupprocess, and then wait forxtrabackupto finish backing up the ibd data files.xtrabackuphas two kinds of threads when backing up InnoDB related data, one is the redo copy thread, which is responsible for copying redo files, and the other is the ibd copy thread, which is responsible for copying ibd files; there is only one redo copy thread, which starts before the ibd copy thread and ends after the ibd thread finishes. When thextrabackupprocess starts execution, it starts the redo copy thread first, which copies the redo logs sequentially starting from the latest checkpoint point; then it starts the ibd data copy thread, and theinnobackupexprocess is in a waiting state (waiting for the file to be created) whilextrabackupcopies the ibd. 3.xtrabackupnotifiesinnobackupex(by creating the file) when it finishes copying the idb, and enters the wait state itself (the redo thread still continues copying);innobackupexreceives notification fromxtrabackup, executesFLUSH TABLES WITH READ LOCK(FTWRL), gets the consistency bit, and then starts backing up non-InnoDB files (including frm, MYD, MYI, CSV, opt, par, etc.). In the process of copying non-InnoDB files, because the database is in global read-only state, if you backup in the main library of the business, you should be especially careful, if there are more non-InnoDB tables (mainly MyISAM), the whole library will be read-only for a longer time, and this impact must be evaluated to.- when
innobackupexhas finished copying all non-InnoDB table files, notifyxtrabackup(by deleting the files) and at the same time enter the wait itself (waiting for another file to be created). xtrabackupstops the redo copy thread after receiving notification thatinnobackupexhas finished backing up the non-InnoDB, and then notifiesinnobackupexthat the redo log copy is complete (by creating a file).innobackupexstarts unlocking and executesUNLOCK TABLESonce it receives the redo backup completion notification.- Finally
innobackupexandxtrabackupprocesses each complete their closing tasks, such as releasing resources, writing backup metadata information, etc.innobackupexwaits for thextrabackupsub-process to finish and then exits.
In the file copy described above, the backup process reads the data file directly through the operating system, only interacts with the database when executing SQL commands, basically does not affect the operation of the database, there will be a period of read-only when backing up non-InnoDB (if there is no MyISAM table, the read-only time is around a few seconds), when backing up InnoDB data files, there is no effect on the database at all, it is a real hot backup.
Both InnoDB and non-InnoDB file backups are done by copying files, but implemented in different ways, the former is done at page granularity (xtrabackup), the latter is a cp or tar command (innobackupex), xtrabackup checksum value when reading each page to make sure the data blocks are checksum value when reading each page to make sure the data blocks are consistent, while innobackupex already does a flush (FTWRL) when cp the MyISAM file, and the file on disk is complete, so the data files in the final backup set are written to be complete.
Incremental backups
PXB supports incremental backup, but only for InnoDB, InnoDB each page has an LSN number, LSN is global incremental, the page is changed will record the current LSN number, the larger the LSN in the page, the more recent the current page (recently updated). Each backup will record the current LSN (in the xtrabackup_checkpoints file), incremental backup is to copy only the page whose LSN is larger than the last backup, and skip the smaller ones than the last backup, each ibd file is finally backed up to an incremental delta file.
MyISAM does not have an incremental mechanism, each incremental backup is a full copy.
The incremental backup process is the same as a full backup, except for the ibd file copy.
Recovery process
If you look at the logs for restoring a backup set, you will see that it is very similar to mysqld startup, in fact, the recovery of a backup set is similar to a crash recovery after a mysqld crash.
The purpose of recovery is to restore the data in the backup set to a consistent point, the so-called consistent means that the original database at a certain point in time the state of each engine data, such as MyISAM data corresponds to the 15:00 time point, InnoDB data corresponds to the 15:20, this state of data is inconsistent. PXB backup set corresponds to a consistent point, is the time point of the backup PXB backup set corresponds to the point in time when the backup FTWRL, the restored data, it corresponds to the original database FTWRL when the state.
Because after the backup FTWRL, the database is in read-only, non-InnoDB data is copied in the case of holding a global read lock, so the non-InnoDB data itself corresponds to the FTWRL time point; InnoDB ibd file copy is done before FTWRL, copy out of the different ibd file last updated at different points in time, this state of the ibd file is not directly available, but redo log is continuously copied from the beginning of the backup, and the last redo log point is obtained after holding FTWRL, so the final ibd data time point after applying through redo is also consistent with FTWRL.
So the recovery process involves only the recovery of InnoDB files, non-InnoDB data is not moving. After the backup recovery is complete, you can copy the data files to the corresponding directory, and then start through mysqld.
Reference:
 微信
微信 支付宝
支付宝



